I'm super happy and grateful to share that I've recently completed my PhD!
Looking back, the past five years at SymbioticLab have been an intense mix of joy, frustration, discovery, and growth.
As I close this chapter, I wanted to take a moment to reflect — to write down some of the lessons, thoughts, and shifts I've experienced, especially in the world of MLSys.
This post is adapted from the conclusion section of my thesis (User-Centric Machine Learning Systems), hopingthat they might resonate with or support future researchers walking a similar path.
When I started my PhD in 2020, AI was largely limited to niche domains like image recognition and recommendation systems, primarily utilized by large corporations or research labs.
Today, in the year of 2025, it becomes a technology that seamlessly integrates into individuals' everyday life and professional workplace.
When AI interfaces with individuals through text, audio, images, video, and physical interactions, we need to rethink: How should we architect the new generation of ML systems to balance user-centric experiences with server-side efficiency.
Over the past five years, we have witnessed the rapid expansion of AI from a technology confined to specialized domains within large corporations and research labs to a tool that is increasingly integrated into the everyday life of individuals. This shift, accelerated by advancements in generative AI models such as ChatGPT, signifies a clear trend: AI is moving towards ubiquity, poised to become as commonplace in our daily existence as essential utilities like water, electricity, and the internet. With this trend, it necessitates a rethinking of its role in people's life and, consequently, how we design the underlying systems to support this integration.
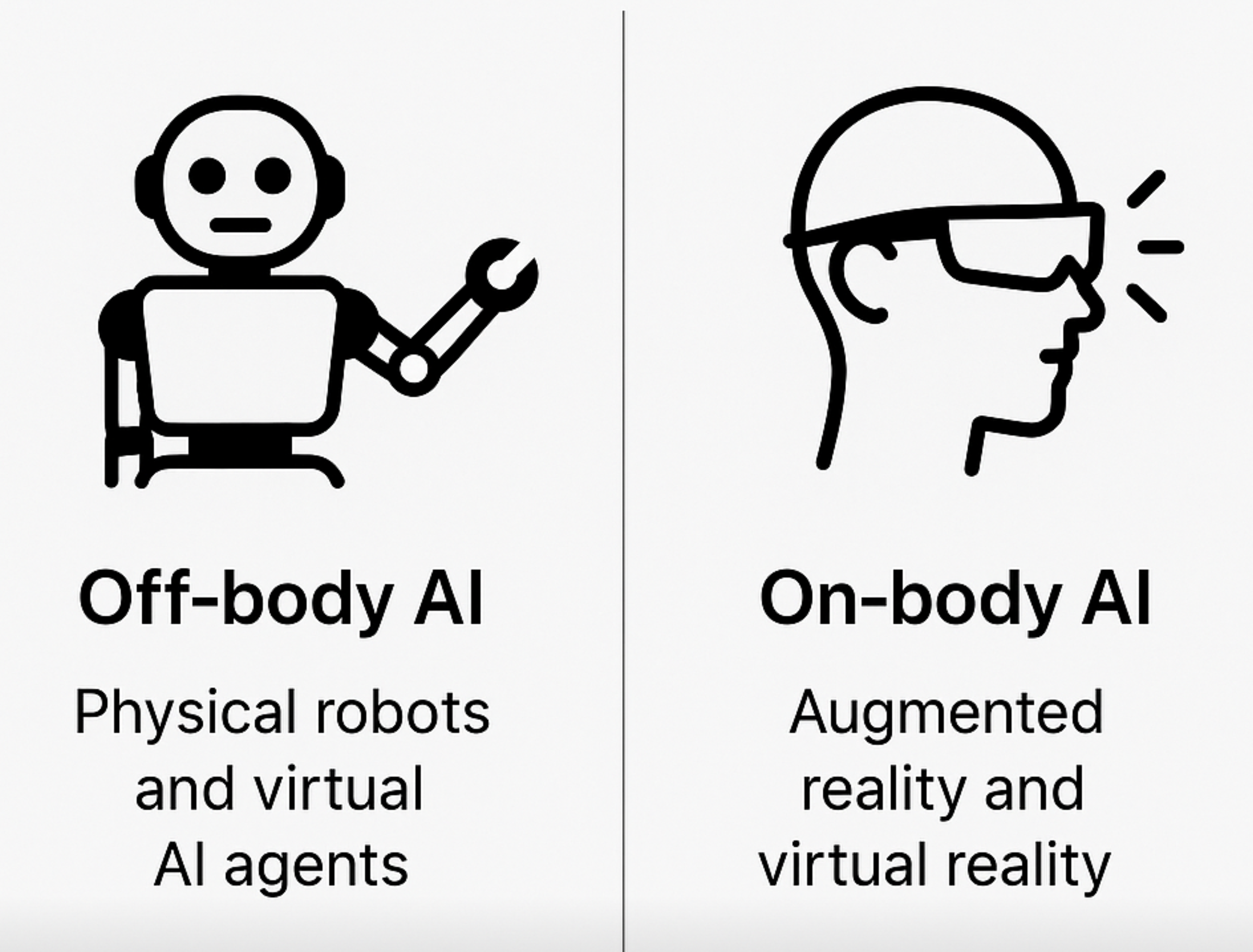
Looking forward, the medium through which AI delivers its value to humans will likely evolve beyond current chat-based interfaces where users proactively submit requests. Two prominent future mediums emerge:
Off-body AI: Physical robots and virtual AI agents designed to proactively complete complex tasks in the physical or digital world in an autonomous and goal-oriented manner. Their functionalities extend beyond simple command execution to complex reasoning, planning, and execution across diverse domains. Imagine an advanced cleaning robot with the ability to understand spoken commands, sophisticated vision to identify objects and a dexterous arm to manipulate items.
On-body AI: Augmented reality (AR) and virtual reality (VR) running on wearable devices such as smart glasses. This form of AI would function more like an ever-present, invisible daily assistant, subconsciously learning user habits and contexts to offer timely suggestions and support. For instance, in a professional setting, it could understand an individual's tasks and provide context for upcoming meetings, summarize discussions, or even act as a co-pilot in various professions.
Figure 1: The Future Mediums of Pervasive AI
To enable these sophisticated off-body and on-body AI experiences, a confluence of advanced technologies is necessary. These include advanced LLMs for natural language understanding and high-level planning, multimodal models for perception (e.g., vision, audio processing), reinforcement learning for dynamic decision-making in complex environments, and sophisticated control systems for robotic manipulation.
These evolving interaction paradigms not only underscore the future where AI is deeply and proactively embedded in our daily activities but also directly inspire the future research directions in ML system design to support such pervasive AI, where I will discuss the underlying challenges and opportunities in the Future Work section.
Lessons Learned for ML Systems
The evolving landscape of ML underscores the critical role of ML systems, which are essential for enabling these emerging AI applications. Throughout my research journey, I continually reflect on the current ML systems landscape, asking:
What kind of ML systems research deserve us to dive deeper?
How do we find promising ML systems problems to solve?
How should we approach these problems?
Below, I share my thoughts to the questions, hoping they are helpful for future researchers. For those interested in exploring the broader landscape of ML systems research, I also maintain a curated Paper List that covers various aspects of generative AI systems research.
Conceptual Stages of ML Systems Innovation
Through my reflection of numerous ML systems projects, I've found three conceptual levels of research:
Research Phase
Focus Area
Primary Driver
0→1: Foundational Research
New ML Use Cases & System Needs
Academia
1→2: Practical Enhancement
Scalability, Performance & Robustness
Academia–Industry Collaboration
2→∞: Efficiency Optimization
Aggressive Efficiency Squeeze & Cost Reduction
Industry
Table 1: Conceptual Stages of ML Systems Innovation
0→1: This represents the most pioneering research, often best pursued in academic settings. It involves addressing entirely new ML use cases, applications, or workloads for which no existing system adequately caters to their unique objectives, resource constraints, or workload characteristics. The novelty lies in being the first to identify these distinct system design requirements and to build a foundational solution. For instance, my work on Venn [3], Curie [4] and Exp-Bench [5] exemplify 0→1 research by identifying and addressing previously unarticulated system needs for emerging ML paradigms.
1→2: Once a foundational (0→1) system or concept exists, the next critical step is to enhance its practicality and efficiency. This phase focuses on making the system scalable, robust, and more performant. It's about transforming an initial proof-of-concept into something that is not just usable but also efficient under realistic conditions. This stage of research is also valuable and well-suited for doctoral exploration and industry collaboration, as it involves deep thinking and understanding of emerging ML workloads along with underlying resources to bridge the gap between novel concepts and practical applications. My contributions such as Andes [2], Fluid [1], and FedScale [7] fall into this category, building upon foundational ideas to deliver more performant systems capable of handling realistic workloads, and running with advanced resource scheduler and scaling to heterogeneous resources.
2→∞: This level involves the intensive effort required to make an ML system truly viable for large-scale, real-world industrial deployment. The primary focus here is on aggressively optimizing efficiency—cutting operational costs, maximizing resource utilization, and minimizing latency or training time. While critically important for widespread adoption, this phase often demands substantial engineering resources and domain-specific expertise, making it particularly well-suited for industry teams who possess the scale and focused incentives for such deep optimization. This distinction is perhaps particularly salient in ML systems, where academia and industry often collaborate or drive parallel innovations, especially with the rapid, real-world impact seen in fields like Generative AI. My projects like Auxo [6] and FedTrans [8] further improve the system and model efficiency via techniques like customized ML model training based on the underlying compute resources and data characteristics.
Think Ahead
Given the rapid pace of innovation in AI, it is crucial to think ahead and proactively position your research to address future needs. While ML systems play an indispensable role in enabling ML advancements—and can sometimes even drive new ML capabilities, akin to the 'hardware lottery' concept—they often serve a supporting role, following the advancements of ML models and algorithms. In fast-moving and competitive areas like Generative AI, where new ideas can quickly reshape the landscape, a reactive approach can leave research feeling disempowered. Therefore, it's vital for systems researchers not only to address current popular ML challenges but also to explore ML technologies and use cases that are likely to emerge and become significant in the next three to five years, or even further out. This foresight, as demonstrated by my pivot towards supporting Generative AI during my PhD, can lead to more impactful and enduring research contributions. Proactively seeking and integrating insights from industry trends, where possible, can further sharpen this forward-looking perspective.
Figure 2: Timeline of key focus areas in AI research
Specialized System Design
As AI continues to diversify, we encounter an expanding array of ML use cases, each possessing unique objectives and resource characteristics. These specialized demands present both unique challenges and significant opportunities for innovation. Therefore, when designing ML systems, it is often necessary to think from first principles—to challenge existing assumptions and identify the fundamental building blocks required for a given workload. For instance, my work on Fluid [1] highlighted the unique requirements of experimental model training, where the primary objective shifts from minimizing job completion time to optimizing makespan, as comprehensive evaluation across numerous training jobs is needed to identify optimal configurations. Similarly, Andes [2] was designed specifically for the emerging demands of AI conversational services, focusing on user-perceived Quality-of-Experience (QoE) rather than traditional system metrics such as request throughput.
Future Work
Looking ahead, the principles of user-centricity for pervasive AI and the lessons learned for ML systems research guide my vision for future work. The following directions focus on long-term opportunities that align with the anticipated trends in pervasive ML, primarily emphasizing foundational (0→1) and practicalization (1→2) research to pioneer and solidify the next generation of user-centric ML systems.
Advancing User-Centricity and Quality of Experience (QoE) Across Diverse Modalities
Inspired by the vision of pervasive AI (both off-body and on-body AI) and the proliferation of multimodal generative models, a primary direction for future work is to extend the principles of user-centric system design with the concept of Quality of Experience (QoE) as explored in Andes [2], to a broader spectrum of ML applications and modalities. As AI-driven generation and understanding of images, audio, and video become increasingly integrated into daily life, it is crucial to pivot system design objectives to prioritize the user's direct experience with these rich media.
Defining and Optimizing Modality-Specific QoE Metrics
Quantifying user experience for non-textual modalities requires thoughtful design. Future work must first formulate QoE metrics that align closely with the specific goals of underlying ML applications and the nuanced expectations of users.
On the content quality side, this includes the perceptual quality of generated images, the temporal coherence and narrative consistency of generated video, the fidelity of audio synthesis, and the accuracy and relevance of video understanding outputs—all from a user's perspective.
On the system efficiency side, this translates to optimizing for interactive responsiveness (e.g., time-to-first-token/image/frame, content delivery timeline), consistent content delivery across different modalities or transitions between them, overall system responsiveness under varying loads, and resource efficiency (e.g., energy, compute) in meeting target QoE levels.
When it comes to on-body AI who acts subconsciously, a user-centric ML system should know the best timing of interaction based on various user's preferences.
Based on the defined QoE metrics, systems should ideally adapt QoE goals based on individual user preferences (e.g., tolerance for artifacts versus speed), task context (e.g., rapid prototyping versus final production), or even user expertise level. This necessitates research into adaptive scheduling algorithms that can dynamically adjust system behavior and resource allocation to meet these personalized QoE targets.
Resource Management for Dynamic Generative Workloads
The computational demands of generative models, especially during interactive use, can be highly variable and unpredictable. For instance, an on-body AI assisting with visual tasks typically consumes minimal resources during passive observation. However, its resource demand can spike dramatically when the user poses a complex query (e.g., 'Summarize the key activities in this busy street market') about a dynamic and intricate environment. The complexity of both the environment (e.g., number of objects, rate of change) and the user's request (e.g., level of detail, reasoning required) directly dictates the necessary computational power for perception, understanding, and response generation.
Additionally, the memory footprint, computational intensity, and access patterns across modalities vary significantly (e.g., LLMs versus image diffusion models versus vision encoder models), developing specialized system components and resource allocation strategies tailored to each modality is essential. This includes dynamic memory allocation for large models, adaptive batching strategies for variable arrival rates, specialized deployment strategies for different modalities, and efficient offloading mechanisms between edge and cloud resources. New resource management techniques and system designs will be needed to deliver responsive user interaction for such dynamic and resource-intensive generative tasks.
Cross-Modal QoE Synchronization
As applications increasingly blend multiple modalities (e.g., a robot assistant that visually perceives its environment, verbally plans its actions, and then physically interacts), ensuring a consistent and high-quality experience across these interconnected components will be a significant system design challenge. For instance, a system might need to ensure that visual understanding (e.g., identifying an object in a user's view) is tightly synchronized with concurrent auditory cues or interactive elements (e.g., highlighting the object on an AR display) to provide a seamless and coherent experience. This requires novel scheduling algorithms that understand inter-modal dependencies and optimize for a holistic and synchronized QoE.
AI Agents for Self-Evolving ML Systems Design
The emergence of AI agents capable of performing complex tasks autonomously presents a transformative opportunity, potentially facilitating scientific research and accelerating innovation. My last-year work on building a co-scientist AI agent to help automate research experimentation and optimize the research solutions - Curie [4] - has shown the potential of this direction. Key capabilities and research opportunities include:
Automated System Design and Optimization: AI agents could be tasked with discovering optimal system configurations (i.e., 2→∞ research level tasks), such as the optimal degrees of different parallelisms (e.g., tensor, pipeline, data parallelism) for training LLMs, navigating vast and complex search spaces more effectively to find the optimal system configurations that maximize training throughput. Many 2→∞ tasks—those requiring significant, detailed engineering effort to squeeze out final percentages of performance or cost savings—could potentially be delegated to AI agents. This would free human researchers and engineers to focus on more foundational 0→1 or 1→2 challenges, accelerating the pace of innovation in ML systems. Beyond 2→∞ configuring systems, agents might propose and even implement novel system components or designs (contributing to 0→1 and 1→2 research levels). Such agents could propose innovative architectural components, autonomously adapt systems to evolving workloads and hardware, contributing to novel scheduling policies, kernel-level optimizations, or advanced strategies for computation-communication overlap.
Autonomous Benchmarking, Analysis, and Refinement: An AI agent could be empowered to deploy system changes, execute over diverse benchmark workloads, collect and analyze performance traces, and iteratively refine its designs based on observed outcomes, creating a closed loop of continuous system improvement. A fundamental challenge will be developing ways for AI agents to represent and understand the intricate components, traces, and performance characteristics of complex ML systems.
Achieving this level of autonomous capability requires a new generation of foundation models, which are imbued with deep, specialized knowledge of ML systems. In addition, reinforcement learning is needed to train agents to master the full lifecycle of ML systems research experimentation. This necessitates high-quality datasets that capture end-to-end experimentation processes—including hypothesis generation, system implementation, execution, and analysis—to provide effective training supervision for such agents.
Next-Generation Agentic AI Systems
As AI agents become capable of tackling increasingly complex and long-running tasks, the underlying system frameworks must evolve significantly. Current AI agents often rely on relatively simple sequences of API calls, but future agents will need to perform more sophisticated tool use (e.g., dynamically composing software libraries, executing generated code), interact robustly with physical environments via sensors, manage long-horizon tasks involving intricate dependencies and error recovery, and strategically leverage heterogeneous compute resources. This necessitates re-designing agentic AI system frameworks from the ground up to natively support these advanced agentic capabilities. A key focus will be on creating abstractions that simplify the programming and orchestration of complex agentic workflows. This includes:
Intelligent Resource Management: Agents will decompose high-level goals into many sub-tasks, each potentially requiring different computational resources (e.g., LLM inference, symbolic reasoning, code execution, physical actuators). The framework must provide abstractions to seamlessly dispatch these sub-tasks to appropriate resources, whether local, cloud-based, or on specialized hardware. To execute complex plans efficiently, agents will need to perform multiple sub-tasks, which may run in parallel or sequentially, often forming a Directed Acyclic Graph (DAG) of operations. The underlying system must offer intuitive ways to express and manage this parallelism, handling dependencies, data flow, and synchronization automatically where possible. Moreover, advanced scheduling are needed for interdependent sub-tasks and underlying resources to optimize for latency, cost, or other objectives, ensuring robust execution of long-running, multi-step agentic workflows. Finally, robust checkpointing and fault tolerance mechanisms will be essential to ensure the reliable execution of these potentially long-running and complex multi-step agentic workflows.
Self-Evolving Agent Systems: As agentic systems undertake longer-running tasks and operate in dynamic environments, they should possess the ability to learn and adapt continuously. The framework should support agents that learn from their past actions, environmental feedback, and direct human input. This involves integrating mechanisms akin to reinforcement learning, where agents can refine their policies, improve their planning abilities, and even discover new tools or strategies over time. Training AI agents that learn complex behaviors and adapt over long periods requires significant advancements in RL techniques and systems. This includes developing algorithms that are more sample-efficient to learn from limited interaction data, computationally scalable to handle complex state and action spaces, and capable of effective reward assignment over extended time horizons. From the systems perspective, this implies building resource-efficient infrastructure for distributed RL training and memory management for past agent experiences.
By tackling these system-level challenges, we can enable the development of more capable, adaptable, and reliable AI agents that can address complex, real-world problems across a multitude of domains.
Citation
@phdthesis{amberljc:dissertation,
author = {Jiachen Liu},
title = {User-Centric Machine Learning Systems},
year = {2025},
month = {June},
institution = {University of Michigan},
}
[9] Evaluation Framework for AI Systems in "the Wild", Sarah Jabbour, Trenton Chang, Anindya Das Antar, Joseph Peper, Insu Jang, Jiachen Liu, Jae-Won Chung, Shiqi He, Michael Wellman, Bryan Goodman, Elizabeth Bondi-Kelly, Kevin Samy, Rada Mihalcea, Mosharaf Chowdhury, David Jurgens, Lu Wang. Arxiv 2025.
[10] Efficient Large Language Models: A Survey, Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang. TMLR 2024.