AI Research Engineering skills
The engineering layer for AI research agents.
Today's AI research demands excellence in two distinct areas: algorithmic innovation and systems engineering. Unfortunately, the systems side often becomes a bottleneck for scientific progress, as researchers spend valuable time wrestling with distributed training configs and data pipelines instead of iterating on their ideas. While AI coding agents promise to help, they frequently stumble in this specialized domain. General-purpose programming capability is not enough when the software ecosystem moves this fast; an agent might write valid Python, but it often lacks the deep, up-to-date context required to navigate the complex, rapidly evolving tools used in modern AI experimentation.
This is the motivation behind our AI Research Engineering Skills Library. We built this open-source project to empower coding agents with the specific, modular engineering knowledge they need to act as capable research assistants. By covering the entire experimental workflow, from preparing high-quality datasets to configuring complex training loops and conducting rigorous evaluations, this library enables agents to handle the heavy lifting of infrastructure software. This allows researchers to stop fighting with frameworks and focus entirely on the science.
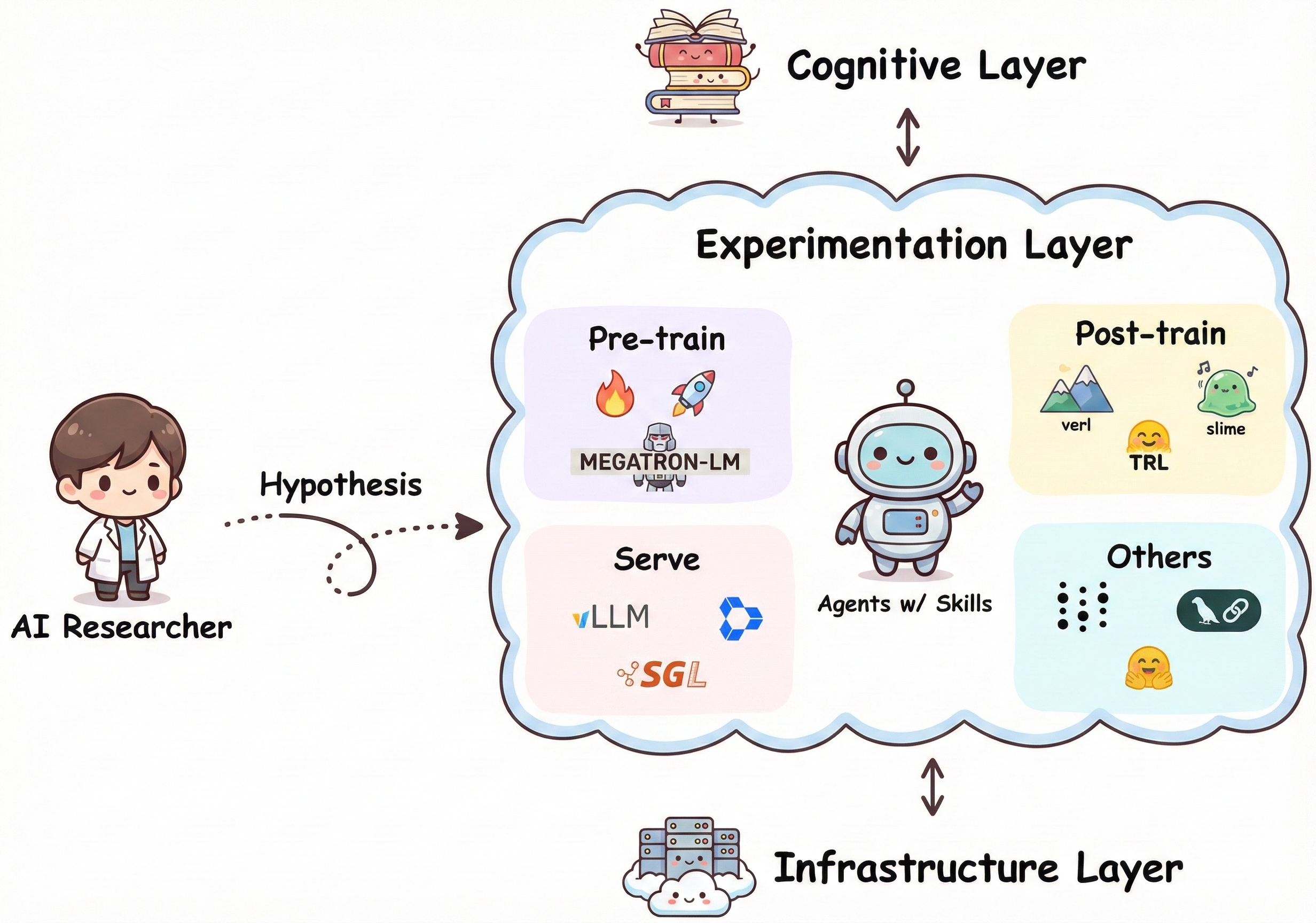
Skills LibraryIntroducing the AI Research Engineering Skills Library
Our AI Research Engineering Skills Library is the most comprehensive open-source library of AI research engineering skills, designed to empower AI agents to autonomously conduct AI research via end-to-end scientific experimentation: preparing datasets, executing training pipelines, deploying models, or analyzing results, just like a real researcher. We believe this is one of the most important puzzles towards a real AI Research Agent.
Our focus is on quality over quantity (82 skills across 20 categories). Each skill offers comprehensive, expert-level guidance complete with real-world code examples, troubleshooting guides, and production-ready workflows.
📦 Quick Install (Recommended)
Use the interactive installer that auto-detects installed agents and offers installation by category or individual skills:
npx @orchestra-research/ai-research-skillsClaude Code Marketplace Alternative
Install individual skills directly from the marketplace:
/plugin marketplace add orchestra-research/AI-research-SKILLs
/plugin install fine-tuning@ai-research-skillsAvailable skills (82 total)
| Category | Skills |
|---|---|
| Model Architecture | litgpt, mamba, nanogpt, rwkv, torchtitan |
| Tokenization | huggingface-tokenizers, sentencepiece |
| Fine-Tuning | axolotl, llama-factory, peft, unsloth |
| Mechanistic Interpretability | transformerlens, saelens, pyvene, nnsight |
| Data Processing | nemo-curator, ray-data |
| Post-Training | fine-tuning-with-trl, grpo-rl-training, openrlhf, simpo, verl, slime, miles, torchforge |
| Safety | constitutional-ai, llamaguard, nemo-guardrails |
| Distributed Training | accelerate, deepspeed, megatron, pytorch-fsdp, pytorch-lightning, ray-train |
| Infrastructure | lambda-labs, modal, skypilot |
| Optimization | awq, bitsandbytes, flash-attention, gguf, gptq, hqq |
| Evaluation | lm-eval-harness, bigcode-harness, nemo-evaluator |
| Inference | llama-cpp, sglang, tensorrt-llm, vllm |
| MLOps | mlflow, tensorboard, weights-and-biases |
| Agents | autogpt, crewai, langchain, llamaindex |
| RAG | chroma, faiss, pinecone, qdrant, sentence-transformers |
| Prompt Engineering | dspy, guidance, instructor, outlines |
| Observability | langsmith, phoenix |
| Multimodal | audiocraft, blip-2, clip, llava, segment-anything, stable-diffusion, whisper |
| Emerging Techniques | knowledge-distillation, long-context, model-merging, model-pruning, moe-training, speculative-decoding |
| ML Paper Writing | ml-paper-writing |
📦 Model Architecture 5 skills
- LitGPT: Lightning AI's library of over 20 clean, optimized LLM implementations with production-grade training recipes.
- Mamba: State-space model with O(n) complexity, up to 5× faster than Transformers.
- RWKV: RNN+Transformer hybrid with infinite context length, now a Linux Foundation project.
- NanoGPT: Andrej Karpathy's educational GPT implementation in ~300 lines of clean code.
- TorchTitan: PyTorch native distributed training framework for large-scale models with composable parallelism.
🔤 Tokenization 2 skills
- HuggingFace Tokenizers: Rust-based tokenization processing at <20s/GB, supporting BPE, WordPiece, and Unigram algorithms.
- SentencePiece: Language-independent tokenization at 50k sentences/sec, used by T5 and ALBERT.
🎯 Fine-Tuning 4 skills
- Axolotl: YAML-based fine-tuning framework supporting 100+ models.
- LLaMA-Factory: WebUI-based no-code fine-tuning platform.
- Unsloth: Optimized library for 2× faster QLoRA fine-tuning.
- PEFT: Hugging Face's Parameter-Efficient Fine-Tuning library for LoRA, QLoRA, and adapters.
🧠 Mechanistic Interpretability 4 skills
- TransformerLens: Library for mechanistic interpretability of GPT-style models with activation patching and causal tracing.
- SAELens: Sparse autoencoder library for understanding neural network features and circuits.
- pyvene: Intervention-based interpretability library for causal analysis of neural networks.
- nnsight: Remote model inspection and intervention for interpretability research at scale.
📊 Data Processing 2 skills
- Ray Data: Distributed ML data processing with streaming execution and GPU support.
- NeMo Curator: GPU-accelerated data curation with 16× faster deduplication.
⚡ Distributed Training 6 skills
- Megatron-Core: NVIDIA's framework for training 2B-462B parameter models with 47% MFU on H100s.
- DeepSpeed: Microsoft's ZeRO optimization suite for memory-efficient training.
- PyTorch FSDP: Native PyTorch Fully Sharded Data Parallelism for large-scale distributed training.
- Accelerate: Hugging Face's 4-line API for managing distributed training with minimal code changes.
- PyTorch Lightning: High-level training framework with structured Trainer class.
- Ray Train: Distributed training orchestration across clusters with fault tolerance and elastic scaling.
🎓 Post-Training 8 skills
- TRL Fine-Tuning: Hugging Face's Transformer Reinforcement Learning library for advanced fine-tuning.
- GRPO-RL-Training: Gold-standard Group Relative Policy Optimization implementation with TRL.
- OpenRLHF: Complete RLHF pipeline built on Ray and vLLM.
- SimPO: Simple Preference Optimization algorithm without requiring a reference model.
- verl: Volcano Engine RL library for scalable RLHF training with hybrid parallelism.
- slime: Lightweight preference learning library for efficient alignment tuning.
- miles: Multi-task instruction learning framework for enhanced skill acquisition.
- torchforge: PyTorch-native toolkit for post-training optimization and model refinement.
🚀 Inference & Serving 4 skills
- vLLM: Production-ready high-throughput LLM serving engine with PagedAttention.
- TensorRT-LLM: NVIDIA's fastest inference engine achieving 24k tokens/sec with FP8/INT4 quantization.
- llama.cpp: CPU and Apple Silicon inference with GGUF quantization support.
- SGLang: Structured generation engine with RadixAttention, 5-10× faster for agent workloads.
🛡️ Safety & Alignment 3 skills
- Constitutional AI: AI-driven self-improvement framework guided by core principles.
- LlamaGuard: Specialized safety classifier for filtering LLM inputs and outputs.
- NeMo Guardrails: Programmable guardrails toolkit with Colang for conversational AI.
📈 Optimization 6 skills
- Flash Attention: 2-4× faster attention mechanism with improved memory efficiency.
- bitsandbytes: 8-bit and 4-bit quantization library for 50-75% memory reduction.
- GPTQ: 4-bit post-training quantization achieving 4× memory reduction with <2% accuracy loss.
- AWQ: Activation-aware Weight Quantization for efficient 4-bit model compression.
- HQQ: Half-Quadratic Quantization for fast and accurate weight quantization.
- GGUF: GPT-Generated Unified Format for CPU/GPU inference with llama.cpp.
📊 Evaluation 3 skills
- lm-eval-harness: EleutherAI's benchmark standard for evaluating LLMs across 60+ tasks.
- BigCode Harness: Evaluation framework for code generation models with HumanEval, MBPP, and more.
- NeMo Evaluator: NVIDIA's evaluation toolkit for comprehensive LLM assessment.
☁️ Infrastructure 3 skills
- Modal: Serverless cloud for ML with instant GPU provisioning and simple Python SDK.
- SkyPilot: Multi-cloud orchestration for ML workloads with automatic spot instance management.
- Lambda Labs: Cloud GPU platform optimized for deep learning with pre-configured environments.
🤖 Agents 4 skills
- LangChain: Most popular agent framework with 500+ integrations, ReAct pattern implementation.
- LlamaIndex: Data framework for LLM apps with 300+ connectors, RAG-focused architecture.
- CrewAI: Multi-agent orchestration framework for collaborative AI workflows.
- AutoGPT: Autonomous AI agent framework for goal-driven task completion.
🔎 RAG 5 skills
- Chroma: Open-source embedding database, local/cloud deployment, 24k GitHub stars.
- FAISS: Facebook's similarity search library, billion-scale vectors, GPU acceleration.
- Sentence Transformers: 5000+ embedding models, multilingual support, 15k GitHub stars.
- Pinecone: Managed vector database with auto-scaling and <100ms query latency.
- Qdrant: High-performance vector database with filtering, cloud-native architecture.
🎨 Multimodal 7 skills
- CLIP: OpenAI's vision-language model with zero-shot classification, 25k GitHub stars.
- Whisper: Robust speech recognition supporting 99 languages, 73k GitHub stars.
- LLaVA: Vision-language assistant with image chat capabilities at GPT-4V level.
- Stable Diffusion: State-of-the-art text-to-image generation with ControlNet support.
- Segment Anything: Meta's foundation model for image segmentation tasks.
- BLIP-2: Bootstrapped language-image pre-training for vision-language understanding.
- AudioCraft: Meta's audio generation library for music and sound effects.
✍️ Prompt Engineering 4 skills
- DSPy: Programming framework for optimizing LM prompts and weights declaratively.
- Instructor: Structured output extraction from LLMs using Pydantic models and validation.
- Guidance: Structured output generation with handlebars templates and role-based parsing.
- Outlines: Constrained generation library with regex and JSON schema support.
📟 MLOps 3 skills
- MLflow: Complete ML lifecycle management with experiment tracking and model registry.
- Weights & Biases: ML experiment tracking with real-time visualization and collaborative dashboards.
- TensorBoard: TensorFlow's visualization toolkit for tracking metrics and model graphs.
👁️ Observability 2 skills
- LangSmith: LLM observability platform with tracing, debugging, and prompt versioning.
- Phoenix: Open-source LLM observability with tracing, evaluation, and dataset management.
🔬 Emerging Techniques 6 skills
- MoE (Mixture of Experts): Sparse model architecture activating only relevant experts per token.
- Model Merging: Techniques for combining multiple fine-tuned models into a single model.
- Long Context: Methods for extending context windows beyond standard limits.
- Speculative Decoding: Accelerated inference using draft models for parallel token generation.
- Knowledge Distillation: Transferring knowledge from large models to smaller, efficient ones.
- Model Pruning: Removing redundant weights to create smaller, faster models.
📝 ML Paper Writing 1 skill
- ML Paper Writing: Publication-ready LaTeX templates, citation verification, and writing guidance for NeurIPS, ICML, ICLR, ACL, AAAI, and COLM.
The Philosophy Behind Skills
Think of skills as invocable knowledge packages: modular units that contain structured instructions, references, and resources for a specific domain. This concept, pioneered in the transition from Claude's claude.md to skills, marks a new era of modular intelligence. Regardless of future model architectures or context window sizes, this design principle will remain a cornerstone of AGI: separating lightweight reasoning from heavy resource retrieval.
Key ideas:
- Instant invocation mechanism: Instead of loading all tool descriptions into the model at once, a dedicated tool retriever dynamically searches and loads the right one when needed, just like browsing functions in a directory.
- Reduced context burden: Tool information is injected only when relevant, avoiding context overflow and resource waste while improving reasoning focus and response efficiency.
- Higher precision and quality: On-demand loading ensures the model only uses the most relevant tools, reducing interference and miscalls, leading to more focused and interpretable outputs.
- Simplified version management: Tools can be updated or replaced directly without complex version control, keeping the system lightweight and flexible.
Imagine giving Claude, or any advanced model, a set of skills encapsulating a financial analyst's tools, experience, and workflows. You'd essentially create an AI financial analyst. Extend this to every knowledge domain, and a Skills Marketplace becomes a true digital labor market, capable of simulating any professional role.
As Dario Amodei once emphasized, the simplest solutions often scale the furthest. Skills are precisely that: a simple but transformative step toward general intelligence.
Research Skills in Production
Demo: Reproducing Cutting-Edge LoRA Research
Want to see these research skills in action? I used the GRPO-RL-Training and PPTX skills from this library to reproduce Thinking Machines Lab's cutting-edge LoRA research, complete with GPU provisioning, experiment tracking, and automated presentation generation.
In just 2 days (instead of the typical 2-3 weeks), I validated their findings on both supervised fine-tuning and reinforcement learning tasks, generated publication-ready plots, and delivered a comprehensive analysis, all through natural language conversations with Orchestra.
Read the full demo →Democratizing AI Research
We open-sourced this collection of AI Research Engineering Skills because we believe that AI research should not be a privilege any more. Our goal is to democratize the entire AI research workflow, making it accessible to anyone with curiosity, not just those with compute clusters or elite research engineering teams.
By encapsulating AI research engineering knowledge into reusable, modular, and invocable skills, a student, a startup founder, or a cross-disciplinary researcher in a developing region can now use the same experimental capabilities as top AI labs: launching large-scale training, evaluating models, and running reproducible experiments with the help of AI agents.
A Future Without Gatekeepers
We envision a future where every individual can contribute to AI research, where the frontier of science is no longer gated by hardware or institutional privilege, but powered by collective intelligence and creativity. The AI Research Engineering Skills Library is our contribution to this vision: a step toward a world where groundbreaking research is limited only by imagination, not resources.
Explore the AI Research Engineering Skills Library on GitHub,
and start conducting AI research experiments by just prompting Orchestra Research.