When LLMs Grow Hands and Feet, How to Design our Agentic RL Systems?
TL;DR
The paradigm for training LLMs has shifted from simple-response tasks to complex, multi-step problem-solving driven by AI agents. Previous Reinforcement Learning (RL) frameworks (verl, slime, etc.) for chat LLM are not natively for this new paradigm because they can't handle the heavy computational and resource needs of agentic tasks. This blog post answers three key questions:
- How is RL for LLM-based agents different from traditional RL for chat LLM?
- What are the critical system challenges in adapting RL systems for LLM-based agents?
- What solutions are top research labs or industry developing to address these challenges?
This year, with the rise of AI agents, the frontier of AI has moved from simple-response generation toward solving complex, multi-step problems. Researchers start developing "Agentic Intelligence"—the ability to autonomously plan, reason, and act within dynamic environments. This evolution requires models that can strategize for long-horizon tasks, use tools like code interpreters and web search, and adapt based on environmental feedback.
A useful analogy is to think of LLMs as the "brain" and the LLM-based agent as the "body and hands." In the early phase of LLM development, research focused almost exclusively on the brain—refining reasoning ability. But to solve real tasks, the brain must now direct actions through a body: interacting with sandboxes, executing code, browsing the web, or running experiments. For instance, a scientific discovery agent may need to autonomously design and execute machine learning experiments on GPUs, while a coding agent must safely compile and run code inside isolated containers. This new level of capability requires RL training pipelines purpose-built for long-horizon, tool-rich, open-ended environments.
The Bottleneck: Why Existing RL Frameworks Fall Short
Simply plugging the AI agent rollout into a traditional LLM RL framework doesn't work. These frameworks were designed for simple, stateless LLM rollouts and crumble under the diverse and demanding needs of agents.
The challenge is that agents require both brain and body: while the LLM handles reasoning, the agent's "hands" involve external environments, APIs, or compute resources. Each environment may impose heavy and heterogeneous requirements:
- A coding agent needs an isolated Docker container with a specific file system and dependencies to safely execute code.
- An ML engineering agent might require dedicated GPU access and run long-running experiments.
- A web search agent …
Running even modest batches of such agents (e.g., 128 parallel rollouts) on a local node is impossible if each requires a dedicated Docker container or specialized resource. On the other hand, because of local constraints, existing frameworks run very small batches (e.g., 8), which underutilizes the LLM serving systems and slows down the agent rollout.
| Feature | Traditional LLM RL (The "Brain") | Agentic RL (The "Brain and Body") |
|---|---|---|
| Primary Goal | Optimize single‑turn language quality (helpfulness, style, safety) via preference/reward fine‑tuning. | Solve complex, multi-step problems autonomously in a dynamic environment. |
| Task Horizon | Single turn & stateless. A single prompt leads to a single response. | Multi-turn & stateful. An agent takes a sequence of actions, and its state persists across steps. |
| Interaction Model | The LLM generates text. A reward model scores the final output. | The agent uses tools, calls APIs, executes code, and interacts with external systems. |
| Resource Demand | Lightweight (prompt + reward model). | Heavyweight, diverse, and external (code interpreters, sandbox, web browsers). |
| Key System Bottleneck | LLM inference throughput and reward model scoring. | Orchestrating and scaling diverse, resource-intensive environments for parallel rollouts. |
The Decoupled Solution: Introducing the "Agent Layer"
To solve these challenges, a new system design is emerging that introduces a dedicated Agent Layer. This layer sits between the RL framework (including the inference engine and training engine) and the agent's execution environment, acting as a specialized scheduler and orchestrator for agent tasks.
- The RL Framework focuses on what it does best: training the model and serving LLM inference requests via a standard API.
- The Agent Execution Environments run independently on distributed machines, providing the sandboxes and tools the agent needs.
- The Agent Layer is the bridge. It dispatches rollout tasks to agent environments, provides them with the API endpoint for LLM inference, and collects the resulting agent trajectory to send back to a replay buffer for the trainer.
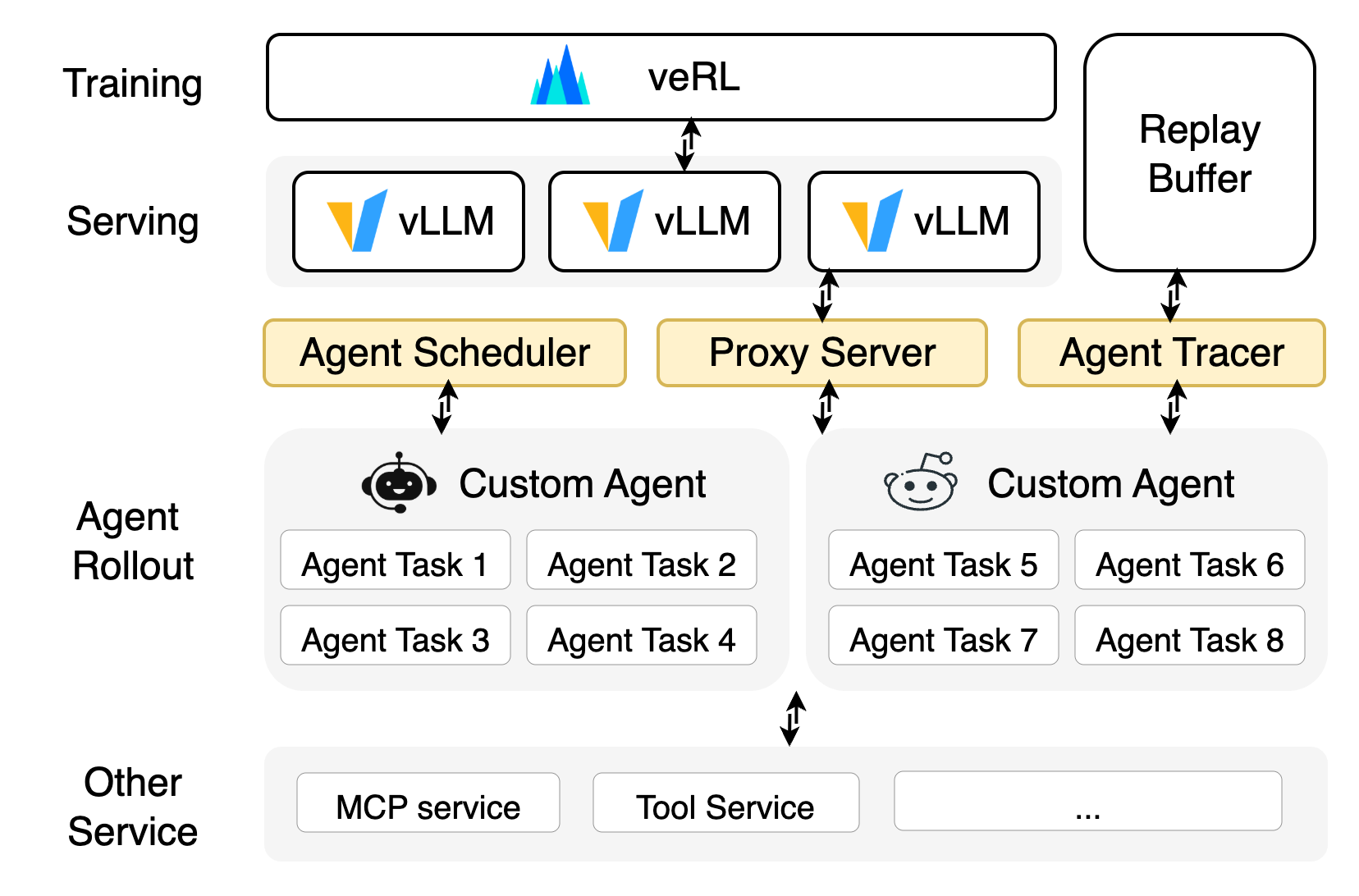
This decoupled architecture underpins agentic RL at scale. Below are three major challenges and emerging solutions.
Challenge 1: Integrating Diverse Agents and RL Frameworks 🧩
The performance of an agentic LLM is deeply tied to its underlying implementation—its prompting scaffold, tool integrations, and environments. A LLM trained with one agent implementation may struggle to generalize to another with a different prompt structure or tool definition. To develop generalized agentic LLMs, the RL training system must support diverse agent implementation without requiring significant code change on the agent side.
Therefore, a critical function of the Agent Layer is to automatically capture agent trajectories for any agent implementation. This is often achieved through a Unified Data Interface. By instrumenting the agent runtime (e.g., by tracing LLM API calls), the system can capture every agent's step. These structured trajectories contain the sequence of states, actions, and rewards from the agent's run.
- State: A snapshot of all critical variables in the agent's environment at a given time.
- Action: The output generated by the LLM, such as a tool call or a final answer.
- Reward: A signal indicating the quality of an action or the final outcome.
This standardized format decouples the agent's implementation logic from the RL framework. The RL framework doesn't need to know how an agent built with LangGraph works; it just consumes the standardized trajectory data. As noted in the Agent-Lightning paper, this design makes the trainer "agent-agnostic" and the agent "trainer-agnostic" [8]. Similarly, GLM-4.5 provides a unified HTTP endpoint, allowing different agent frameworks to write trajectories to a shared data pool [3]. The data pool enables tailored, task-specific filtering and adaptive sampling methods to provide high-quality RL training data for a wide range of tasks. Finally, both Kimi K2 and Kimi-Researcher use a unified, OpenAI Gym-like interface to streamline the addition of new environments and tasks [1, 2].

Challenge 2: Environment Management and Agent Rollout Scalability 🖥️
Training and evaluating agentic LLMs requires massive parallel agent rollouts (e.g. rollout batch size 128 with 4 generations per prompt) across simulated or real environments. Unlike RL for LLM, agentic RL often involves complex, dynamic environments such as sandboxed simulators, external APIs, or sandboxed real-world interfaces, all of which demand careful orchestration of resources. Managing thousands of concurrent environments introduces difficulties in distributed scheduling, state checkpointing, fault tolerance, and reproducibility.
The solution is to offload agent task execution to a dedicated, isolated service that runs separately from the RL training loop.
- Remote Execution Services: Systems like rStar2-Agent and SkyRL use a master/worker architecture where a central scheduler dispatches tasks to a large pool of remote execution workers [5, 7]. This prevents environment interactions from blocking the main training loop and enables massive parallelism.
- Efficient Sandbox Infrastructure: Technologies like Docker and Kubernetes are used to provision isolated environments for each agent run. This practice is highlighted by Kimi-Researcher and GLM-4.5 [2, 3]. Frameworks like Daytona further abstract away the complexities of container management, providing simple APIs for environment provisioning [6]. SkyRL [7] designs a Kubernetes-based setup with storage-optimized instances to cache container images, aidocker + crun runtime for lightweight container execution, which is able to run 80–100 containers per replica on 16-CPU nodes.
- Centralized Environment Pools: For stateful tools like a file system or browser, each task needs its own dedicated environment. AgentFly describes a centralized system that maintains pools of available environments. When a task starts, an environment is allocated from the pool and returned once the task is complete [4]. An environment is allocated to a task and returned to the pool upon completion, minimizing setup latency.
Challenge 3: Handling Long and Complex Tasks ⏳
Agentic tasks are heterogeneous and unpredictable; some finish quickly, while others require dozens of steps and extensive interaction. This variability creates a "long-tail" problem, where a few very long tasks can block the entire training process, leaving expensive GPUs idle while waiting for the slowest rollouts to finish.
- Asynchronous & Decoupled Architecture: A popular design, used by GLM-4.5, Kimi-Researcher, and rLLM, is to partition resources into dedicated rollout engines and training engines [2, 3, 9]. The rollout engines act as producers, continuously generating trajectories and feeding them into a central data pool or replay buffer. The training engines are consumers, asynchronously pulling batches of data from this pool to update the model. SkyRL decomposes agent rollout into a fine-grained three-stage producer-consumer pipeline (initialize, rollout, reward calculation) to maximize parallelism [7].
- Partial Rollouts: For exceptionally long tasks, the "partial rollout" technique is effective. Instead of waiting for a task to finish, the system can pause it, save its state, and resume it in a future iteration with updated model weights. This simple but powerful trick, used by Kimi K2 and Kimi-Researcher, can yield significant speedups [1, 2].
- Dynamic Load Balancing: Statically distributing rollouts evenly across GPUs is inefficient. A more advanced approach, detailed by rStar2-Agent, is a dynamic, load-balanced scheduler [5]. This scheduler assigns rollout requests to GPUs based on their real-time available KV cache capacity. This ensures a balanced workload, preventing both GPU idle time and cache overflows that lead to wasted computation.
The Road Ahead
We are moving towards a future where AI agents don't just think or operate in sandboxes; they help us complete real-world tasks. The solutions of agentic RL systems discussed here are foundational pieces, but not sufficient. Looking forward, agents will have the access to real compute resources to conduct experiments and solve problems autonomously. Several trends are pointing in this direction:
- Algorithmic Advances: System improvements alone cannot solve the challenges of sparse rewards, credit assignment, and sample efficiency.
- Agent-Aware Scheduling: Creating schedulers that understand the specific resource needs and runtime characteristics of different agentic tasks to optimize resource allocation.
- Multi-Agent Systems: Developing systems where multiple agents collaborate or compete to solve even more complex problems.
- Decentralized Agentic RL: Imagine distributing agent rollouts directly to end-users. This would allow agents to learn continuously from human feedback in real-world applications, creating a powerful, personalized learning loop. This, however, brings significant challenges in privacy, security, and ensuring safe exploration.
- Embodied agents & robotics: Extending agentic RL from sandboxes to the physical world introduces hard requirements: complex simulation/real environment, sample efficiency, low-latency control loops with the agent, etc.
The shift from "LLMs that think" to "agents that act" demands new system abstractions. A resilient design pattern is to decouple model training/inference from execution using an Agent Layer, unified trajectory formats, remote execution pools, and asynchronous pipelines. These pieces together let researchers and engineers scale agentic RL without letting environment complexity overwhelm model training.
References
- Kimi K2: Open Agentic Intelligence
- Kimi-Researcher: End-to-End RL Training for Emerging Agentic Capabilities
- GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
- AgentFly: Extensible and Scalable Reinforcement Learning for LM Agents
- rStar2-Agent: Agentic Reasoning Technical Report
- Daytona: Sandbox Infrastructure for Reinforcement Learning Agents
- SkyRL: Train Real-World Long-Horizon Agents via Reinforcement Learning
- Agent Lightning: Train ANY AI Agents with Reinforcement Learning
- rLLM: A Framework for Post-Training Language Agents
How to Cite
If you found this blog post helpful, please consider citing it:
@misc{liu2025agentic,
title={When LLMs Grow Hands and Feet, How to Design our Agentic RL Systems?},
author={Liu, Jiachen},
year={2025},
month={September},
url={https://amberljc.github.io/blog/2025-09-05-agentic-rl-systems.html}
}