Unlocking Capabilities Beyond Pre-training: Fine-Tuning and Other Techniques
Introduction
Machine learning practitioners often encounter large language models that are pre-trained on extensive datasets to predict the next token in a sequence. While these models are powerful, they aren't necessarily optimized for specific tasks or to answer particular questions. That's where fine-tuning comes into play.
During an internal tutorial session on fine-tuning large language models, I realized that there are several essential concepts and techniques worth discussing in-depth. This blog post aims to shed light on multiple ways to enhance your language model's performance, in addition to fine-tuning, and help you make an informed decision about which technique to use for your specific needs.
Prompt Engineering
Prompt Engineering involves carefully crafting the instruction (or 'prompt') given to a language model in order to elicit a specific type of response. By making the prompt more concise, more professional, or geared towards a certain task, we can significantly influence the output of the model.
Example:
- Non-engineered Prompt:
Tell me about climate change. - Engineered Prompt:
Provide a comprehensive, academic-style overview of climate change, focusing on its causes and effects.
Advantages:
- Resource Efficiency: Requires no additional computational cost.
- Precise Control: The prompt allows precise control over what the model generates.
Disadvantages:
- Context Length Limit: Long instructions may exceed the context limit of the model.
- Increased Latency: More tokens in the prompt can increase inference time.
- Lack of Depth: While prompt engineering can steer the model, it does not add any domain-specific depth.
Vanilla Fine-Tuning
Vanilla Fine-Tuning is the process of adapting a pre-trained model to a specific task by further training it on a smaller domain-specific dataset. This method retrains all the model weights and is akin to the original pre-training process, albeit on a more narrow dataset.
Advantages:
- Improved Performance: Gains expertise in the target domain. Leads to more accurate and relevant results for the task at hand.
Disadvantages:
- Resource Intensive: Require the same resources such as GPU memory as in the original pre-training stage.
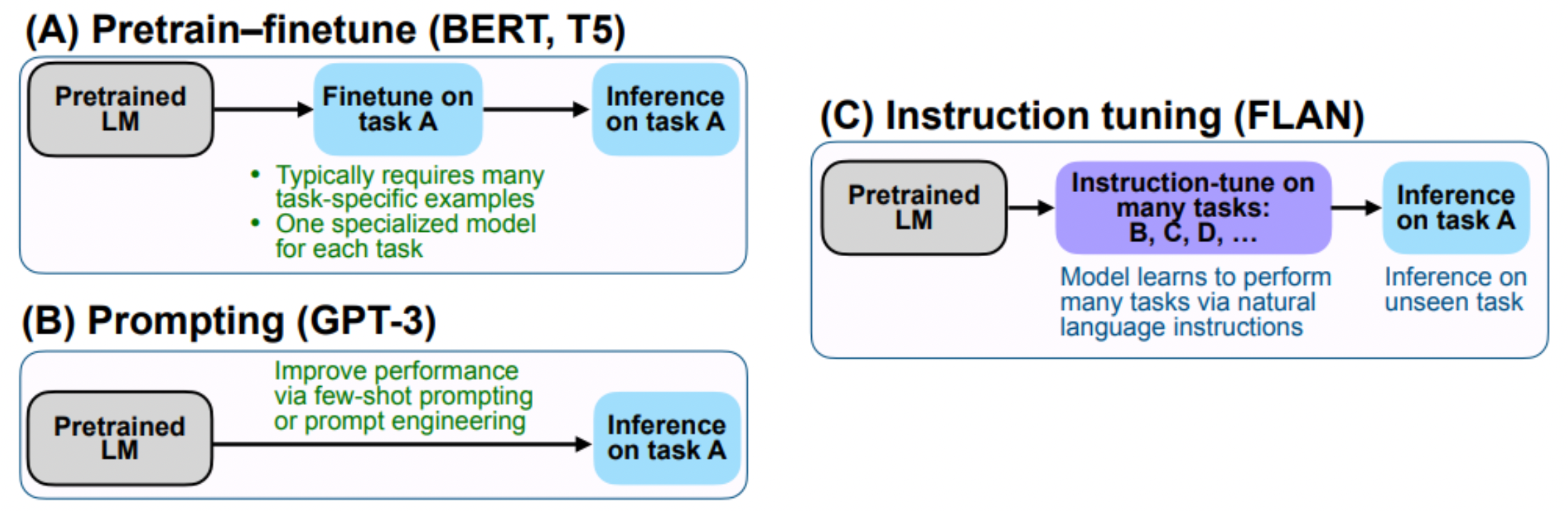
Instruction Tuning
Instruction Tuning primarily utilizes a dataset composed of pairs of instructions and corresponding responses. This approach aims to bridge the gap between the model's generic next-word prediction objectives and the user's specific intent or instructions.
Advantages:
- Predictable Behavior: The model can be conditioned to act in a specific way.
- Versatility: Enables the model to perform tasks it wasn't explicitly trained for.
Disadvantages:
- Dataset Complexity: Requires carefully curated instruction-response pairs.
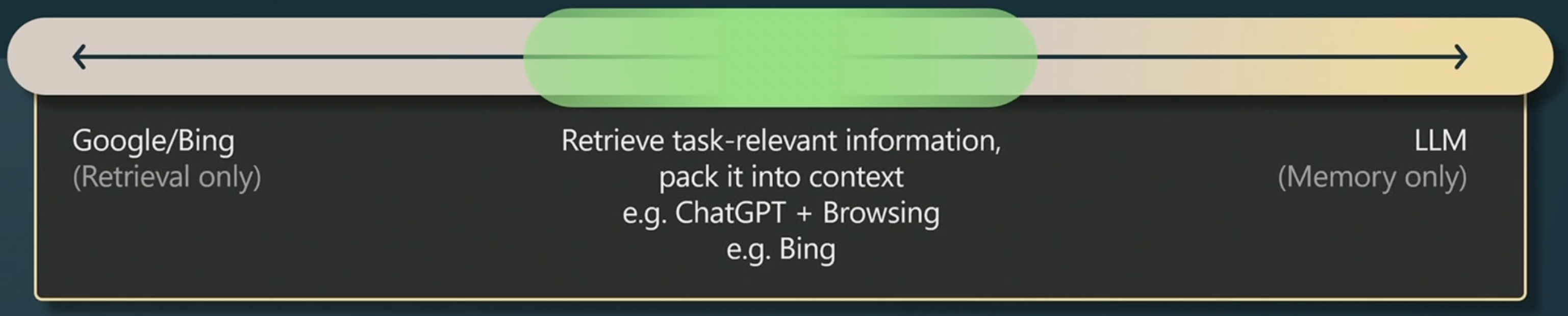
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is an innovative approach that combines the prowess of language models with the ability to pull in external knowledge. In a typical RAG setup, a vector database is used to retrieve context-relevant information, which is then organized into the prompt fed to the language model.
Advantages:
- Enhanced Outputs: Combines internal model knowledge with external databases for richer context.
- Task Versatility: Can be adapted for a variety of tasks where external information is beneficial.
Disadvantages:
- Accuracy of Retrieval: May not always fetch the most relevant or complete information.
- Context Limitations: Can misinterpret the context, leading to irrelevant retrievals.
Parameter-Efficient Fine-Tuning (PEFT)
Parameter-Efficient Fine-Tuning, often abbreviated as PEFT, is a resource-saving alternative to traditional fine-tuning methods. Unlike Vanilla Fine-Tuning, which updates all the model weights, PEFT focuses only on a subset of model weights.
Key Features:
- Resource Efficiency: Lowers the computational and memory overhead.
- Time-Saving: Faster fine-tuning cycles.

Note: We'll dive deeper into PEFT in an upcoming blog post, so stay tuned!
Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning from Human Feedback (RLHF) is a promising but still emerging technique to align large language models more closely with human preferences. The primary goal of RLHF is to incorporate more nuanced behaviors like emotional awareness into the model's responses.
Challenges:
- Unstable Performance: Currently reported to offer inconsistent results.
- Complex Training: Requires highly specialized training setups.
Note: Due to its research-oriented nature and current limitations, we won't delve deep into RLHF in this post. However, it remains an exciting field for future exploration.
Sources
- Challenges and Applications of Large Language Models
- Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
- Microsoft Build Session
- Stanford CS224n Lecture
- LLM Fine-tuning Guide